Una base de datos o banco de datos (en ocasiones abreviada con la sigla BD o con la abreviatura b. d.) es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso. En este sentido, una biblioteca puede considerarse una base de datos compuesta en su mayoría por documentos y textos impresos en papel e indexados para su consulta. Actualmente, y debido al desarrollo tecnológico de campos como la informática y la electrónica, la mayoría de las bases de datos están en formato digital (electrónico), que ofrece un amplio rango de soluciones al problema de almacenar datos.
Existen programas denominados sistemas gestores de bases de datos, abreviado SGBD, que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada. Las propiedades de estos SGBD, así como su utilización y administración, se estudian dentro del ámbito de la informática.
HISTORIA DE LA BASE DE DATOS
HISTORIA DE LA BASE DE DATOS
Historia de los sistemas de bases de datos
El uso de sistemas de bases de datos automatizadas, se desarrollo a partir de la necesidad de almacenar grandes cantidades de datos, para su posterior consulta, producidas por las nuevas industrias que creaban gran cantidad de información.
Herman Hollerit (1860-1929) fue denominado el primer ingeniero estadístico de la historia, ya que invento una computadora llamada “Máquina Automática Perforadora de Tarjetas‿. Para hacer el censo de Estados Unidos en 1880 se tardaron 7 años para obtener resultados, pero Herman Hollerit en 1884 creo la máquina perforadora, con la cual, en el censo de 1890 dio resultados en 2 años y medio, donde se podía obtener datos importantes como número de nacimientos, población infantil y número de familias. La máquina uso sistemas mecánicos para procesar la información de las tarjetas y para tabular los resultados.
Máquina perforadora Herman Hollerit (1860-1929) Tarjetas perforadoras
A diferencia con la maquina de Babbage, que utilizaba unas tarjetas similares, estas se centraban en dar instrucciones a la máquina. En el invento de Herman Hollerit, cada perforación en las tarjetas representaba un número y cada dos perforaciones una letra, cada tarjeta tenia capacidad para 80 variables. La máquina estaba compuesta por una perforadora automática y una lectora, la cual por medio de un sistema eléctrico leía los orificios de las tarjetas, esta tenía unas agujas que buscaban los orificios y al tocar el plano inferior de mercurio enviaba por medio del contacto eléctrico los datos a la unidad.
Este invento disparo el desarrollo de la tecnología, la industria de los computadores, abriendo así nuevas perspectivas y posibilidades hacia el futuro.
Década de 1950
En este lapso de tiempo se da origen a las cintas magnéticas, las cuales sirvieron para suplir las necesidades de información de las nuevas industrias. Por medio de este mecanismo se empezó a automatizar la información de las nóminas, como por ejemplo el aumento de salario. Consistía en leer una cinta o más y pasar los datos a otra, y también se podían pasar desde las tarjetas perforadas. Simulando un sistema de Backup, que consiste en hacer una copia de seguridad o copia de respaldo, para guardar en un medio extraíble la información importante. La nueva cinta a la que se transfiere la información pasa a ser una cinta maestra. Estas cintas solo se podían leer secuencial y ordenadamente.
Década de 1960
El uso de los discos en ese momento fue un adelanto muy efectivo, ya que por medio de este soporte se podía consultar la información directamente, esto ayudo a ahorrar tiempo. No era necesario saber exactamente donde estaban los datos en los discos, ya que en milisegundos era recuperable la información. A diferencia de las cintas magnéticas, ya no era necesaria la secuencialidad, y este tipo de soporte empieza a ser ambiguo.
Los discos dieron inicio a las Bases de Datos, de red y jerárquicas, pues los programadores con su habilidad de manipulación de estructuras junto con las ventajas de los discos era posible guardar estructuras de datos como listas y árboles.
Década de 1970
Edgar Frank Codd (23 de agosto de 1923 – 18 de abril de 2003), en un artículo "Un modelo relacional de datos para grandes bancos de datos compartidos" ("A Relational Model of Data for Large Shared Data Banks") en 1970, definió el modelo relacional y publicó una serie de reglas para la evaluación de administradores de sistemas de datos relacionales y así nacieron las bases de datos relacionales.
A partir de los aportes de Codd el multimillonario Larry Ellison desarrollo la base de datos Oracle, el cual es un sistema de administración de base de datos, que se destaca por sus transacciones, estabilidad, escalabilidad y multiplataforma.
Inicialmente no se uso el modelo relacional debido a que tenía inconvenientes por el rendimiento, ya que no podían ser competitivas con las bases de datos jerárquicas y de red. Ésta tendencia cambio por un proyecto de IBM el cual desarrolló técnicas para la construcción de un sistema de bases de datos relacionales eficientes, llamado System R.
Edgar Frank Codd IBM Corporation Larry Ellison
Década de 1980
Las bases de datos relacionales con su sistema de tablas, filas y columnas, pudieron competir con las bases de datos jerárquicas y de red, ya que su nivel de programación era bajo y su uso muy sencillo.
En esta década el modelo relacional ha conseguido posicionarse del mercado de las bases de datos. Y también en este tiempo se iniciaron grandes investigaciones paralelas y distribuidas, como las bases de datos orientadas a objetos.
Principios década de los 90
Para la toma de decisiones se crea el lenguaje SQL, que es un lenguaje programado para consultas. El programa de alto nivel SQL es un lenguaje de consulta estructurado que analiza grandes cantidades de información el cual permite especificar diversos tipos de operaciones frente a la misma información, a diferencia de las bases de datos de los 80 que eran diseñadas para las aplicaciones de procesamiento de transacciones. Los grandes distribuidores de bases de datos incursionaron con la venta de bases de datos orientada a objetos.
Finales de la década de los 90
El boom de esta década fue la aparición de la WWW “Word Wide Web‿ ya que por éste medio se facilitaba la consulta de las bases de datos. Actualmente tienen una amplia capacidad de almacenamiento de información, también una de las ventajas es el servicio de siete días a la semana las veinticuatro horas del día, sin interrupciones a menos que haya planificaciones de mantenimiento de las plataformas o el software.
Siglo XXI
En la actualidad existe gran cantidad de alternativas en línea que permiten hacer búsquedas orientadas a necesidades especificas de los usuarios, una de las tendencias más amplias son las bases de datos que cumplan con el protocolo Open Archives Initiative – Protocol for Metadata Harvesting (OAI-PMH) los cuales permiten el almacenamiento de gran cantidad de artículos que permiten una mayor visibilidad y acceso en el ámbito científico y general.
Historia y evolución de los distribuidores de bases de datos con énfasis en Ciencia de la Información
Los comienzos de la industria online se remontan a principios de los años 70 en Estados Unidos, con tres organizaciones como pioneras: Lockheed Missiles and Space Company, System Development Corporation y National Library of Medicine. Con el paso de los años, se han ido incorporando nuevos e importantes distribuidores a esta industria, produciéndose cambios significativos en cuanto a nombres, fusiones y adquisiciones, sobre todo de algunos históricos (como BRS, Infoline, Data-Star) . Presentaremos algunos de los distribuidores más importantes que comercializan bases de datos en el área de Ciencia de la Información:
Dialog
La historia de Dialog está íntimamente ligada a la figura de Roger Kent Summit, considerado como el “padre‿ de la industria online, y que trabajó para la Lockheed Missiles and Space Company. En 1966, esta empresa obtuvo un contrato con la NASA (National Aeronautics and Space Administration) para desarrollar un software de recuperación que permitiera buscar de manera rápida y eficaz en sus bases de datos al que se le llamó llamado RECON (Remote Console). En 1969-1970, por encargo de la Atomic Energy Commission, comenzó a gestionar la colección de resúmenes de Nuclear Science.
En 1972, la Lockheed decide explotar su sistema de recuperación de información instalando dos grandes ordenadores que unidos a las principales redes de transmisión existentes (Telenet y Tymnet), dan servicio público tanto en USA como en Europa, convirtiéndose en el primer servicio comercial online del mundo. El sistema se denominó desde entonces Dialog, teniendo su sede central en Palo Alto (California). En agosto de 1988, Dialog es adquirido por Knight-Ridder Inc.; esta misma empresa compra en 1993 el servicio Data-Star, que era el distribuidor europeo más utilizado en 1985 y le estaba haciendo una gran competencia sobre todo en el mercado europeo. En 1995, Dialog Information Services pasa a denominarse Knight- Ridder Information Inc., que en 1997 es comprada por M.A.I.D. plc, pasando a denominarse la fusión de las dos compañías The Dialog Corporation; y ya por último, en Abril del 2000, The Thomson Corporation compra la División de Servicios de Información de The Dialog Corporation, entre los que se encuentran Dialog y Data-Sta r.
Ovid
La historia de Ovid comienza en 1984, cuando su presidente y fundador Mark Nelson desarrolló el software original. En 1985 la compañía pasó a denominarse Online Research Systems, que Nelson cambió a CDP Plus en 1988, y a CDP Technologies Inc. en 1993. En 1994, la compañía adquiere BRS Online Services, y en 1995 cambia su nombre pasando a llamarse Ovid Technologies Inc. OCLC
En 1967, los presidentes de los colegios y universidades del Estado de Ohio fundaron OCLC (Ohio Collage Library Center) con el objetivo de desarrollar un sistema automatizado para que las bibliotecas de las instituciones académicas de Ohio pudieran compartir sus recursos y reducir costes. En 1977, se permitió que otras bibliotecas de fuera de Ohio se convirtieran en miembros de OCLC, pasando a denominarse OCLC Inc. En 1981, el nombre legal de la corporación pasó a ser el de OCLC Online Computer Library Center Inc. En la actualidad, OCLC sirve a más de 30.000 bibliotecas de USA y de otros 65 países. H.W. Wilson En 1984, H.W. Wilson Company introdujo su servicio online por primera vez, proporcionando acceso a sus propias bases de datos, convirtiéndose en un competidor importante de Dialog y BRS.
STN
En 1983, se crea STN (Scientific & Technical Information Network), como consecuencia de la operación conjunta de Chemical Abstracts Service (perteneciente a la American Chemical Society), FIZ Karlsruhe (de Alemania) y Japan Science and Technology Corporation, Information Center for Science and Technology (JICST). Ofrece acceso a bases de datos científicas, técnicas, de negocios y de patentes .
PARTES DE UNA BASE DE DATOS.
las bases de datos, tienen diversas partes, como:
los macros, consulta, modulos, tabla, informe, furmula y formularios.
cada una de estas sirve para formar varias partes de la base de datos.
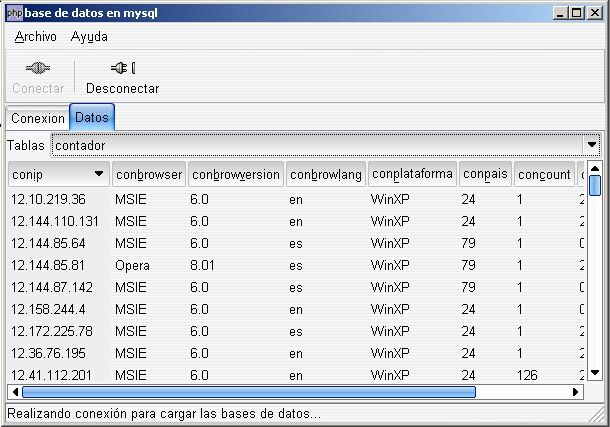
MYSQL
MYSQL
MySQL es un sistema de gestión de bases de datos relacional, multihilo y multiusuario con más de seis millones de instalaciones.1 MySQL AB —desde enero de 2008 una subsidiaria de Sun Microsystems y ésta a su vez de Oracle Corporation desde abril de 2009— desarrolla MySQL como software libre en un esquema de licenciamiento dual.
Por un lado se ofrece bajo la GNU GPL para cualquier uso compatible con esta licencia, pero para aquellas empresas que quieran incorporarlo en productos privativos deben comprar a la empresa una licencia específica que les permita este uso. Está desarrollado en su mayor parte en ANSI C.
Al contrario de proyectos como Apache, donde el software es desarrollado por una comunidad pública y los derechos de autor del código están en poder del autor individual, MySQL es patrocinado por una empresa privada, que posee el copyright de la mayor parte del código.
Esto es lo que posibilita el esquema de licenciamiento anteriormente mencionado. Además de la venta de licencias privativas, la compañía ofrece soporte y servicios. Para sus operaciones contratan trabajadores alrededor del mundo que colaboran vía Internet. MySQL AB fue fundado por David Axmark, Allan Larsson y Michael Widenius.
Historia de MySQL
Empezamos con la intención de usar
mSQL para conectar a nuestras tablas utilizando nuestras propias rutinas rápidas de bajo nivel (ISAM). Sin embargo y tras algunas pruebas, llegamos a la conclusión quemSQL no era lo suficientemente rápido o flexible para nuestras necesidades. Esto provocó la creación de una nueva interfaz SQL para nuestra base de datos pero casi con la misma interfaz API que mSQL. Esta API fue diseñada para permitir código de terceras partes que fue escrito para poder usarse con mSQLpara ser fácilmente portado para el uso con MySQL.La derivación del nombre MySQL no está clara. Nuestro directorio base y un gran número de nuestras bibliotecas y herramientas han tenido el prefijo "my" por más de 10 años. Sin embargo, la hija del co-fundador Monty Widenius también se llama My. Cuál de los dos dió su nombre a MySQL todavía es un misterio, incluso para nosotros.
El nombre del delfín de MySQL (nuestro logo) es "Sakila", que fué elegido por los fundadores de MySQL AB de una gran lista de nombres sugerida por los usuarios en el concurso "Name the Dolphin" (ponle nombre al delfín). El nombre ganador fue enviado por Ambrose Twebaze, un desarrollador de software Open Source de Swaziland, África. Según Ambrose, el nombre femenino de Sakila tiene sus raíces en SiSwate, el idioma local de Swaziland. Sakila también es el nombre de una ciudad en Arusha, Tanzania, cerca del país de origen de Ambrose, Uganda.
DB2
DB2 es una marca comercial, propiedad de IBM, bajo la cual se comercializa un sistema de gestión de base de datos.
DB2 versión 9 es un motor de base de datos relacional que integra XML de manera nativa, lo que IBM ha llamado pureXML, que permite almacenar documentos completos dentro del tipo de datos xml para realizar operaciones y búsquedas de manera jerárquica dentro de éste, e integrarlo con búsquedas relacionales.
La compatibilidad implementada en la última versión, hace posible la importación de los datos a DB2 en una media de 1 o 2 semanas, ejecutando PL/SQL de forma nativa en el gestor IBM DB2
La automatización es una de sus características más importantes, ya que permite eliminar tareas rutinarias y permitiendo que el almacenamiento de datos sea más ligero, utilizando menos hardware y reduciendo las necesidades de consumo de alimentación y servidores.
La memoria se ajusta y se optimiza el rendimiento del sistema, con un interesante sistema que permite resolver problemas de forma automática e incluso adelantarse a su aparición, configurando automáticamente el sistema y gestión de los valores.
DB2 Express-C es la versión gratuita soportada por la comunidad de DB2 que permite desarrollar, implementar y distribuir aplicaciones que no usen las características avanzadas de las versiones comerciales de DB2. Esta versión de DB2 puede ser concebida como el núcleo de DB2, las diferentes ediciones incluyen las características de Express-C más funcionalidades específicas.
DB2 para Linux, UNIX y Windows permite la automatización de tareas, reducción de las necesidades de consumo de alimentación, un alto rendimiento que reduce los servidores necesarios para ejecutar la base de datos, escalabilidad sencilla y alta disponibilidad en su arquitectura de discos de datos y otras soluciones que facilitan la colaboración entre profesionales.
Con aplicaciones que se despliegan y desarrollan de forma sencilla incluso si han sido creadas para utilizarse con otros software de bases de datos.
- - Historia : DB2 UDB no es un producto nuevo. Fue construído en base a dos productos incluídos en el DB2 de AIX en el año 1994: DB2 Common Server, que para propósitos generales incluía funciones avanzadas para el mercado de servidores de bases de datos, con soporte de hardware SMP y OLTP; y el DB2 Parallel Edition, que fue desarrollado para soportar aplicaciones de gran escala, como Data Warehousing y Data Mining.

ACCESS
Microsoft Access es un sistema de gestión de bases de datos relacionales para lossistemas operativos Microsoft Windows, desarrollado por Microsoft y orientado a ser usado en un entorno personal o en pequeñas organizaciones. Es un componente de la suite ofimática Microsoft Office. Permite crear ficheros de bases de datos relacionales que pueden ser fácilmente gestionadas por una interfaz gráfica simple. Además, estas bases de datos pueden ser consultadas por otros programas. Este programa permite manipular los datos en forma de tablas (formadas por filas y columnas), crear relaciones entre tablas, consultas, formularios para introducir datos e informes para presentar la informacion
HISTORIA DE ACCESS
- 1. Historia de Access
- 2. Microsoft Access es un programa Sistema de gestión de base de datosrelacional creado y modificado por Microsoft para uso personal de pequeñas organizaciones. Es un componente de la suite Microsoft Office aunque no se incluye en el paquete "básico". Una posibilidad adicional es la de crear ficheros con bases de datos que pueden ser consultados por otros programas. Dentro de un sistema de información entraría dentro de la categoria de Gestion y no en la de Ofimática como algunos creen.
- 3. Generalidades
- 4. Es un software de gran difusión entre pequeñas empresas (PYMES) cuyas bases de datos no requieren de excesiva potencia, ya que se integra perfectamente con el resto de aplicaciones de Microsoft y permite crear pequeñas aplicaciones con unos pocos conocimientos del Programa.Microsoft Access permite crear formularios para insertar y modificar datos fácilmente. También tiene un entorno gráfico para ver las relaciones entra las diferentes tablas de la base de datos.Tiene un sistema de seguridad de cifrado bastante primitivo y puede ser la respuesta a proyectos de programación de pequeños y medianos tamaños.,km n,nm
- 5. Historia
- 6. Access versión 1.0 fue liberado en noviembre de 1992, rápidamente en mayo de 1993 se liberó Access 1.1 para mejorar la compatibilidad con otros productos de Microsoft e incluir el lenguaje de programación de Access Basic.Microsoft especifica los requisitos mínimos de hardware para el Access v2.0: Microsoft Windows v3.0 con 4 MB de memoria RAM necesaria, 6 MB de RAM recomendados, 8 MB de espacio disponible en disco duro necesario, 14 MB de espacio en disco duro recomendado. El producto se entregará en siete disquetes de 1,44 MB. El manual muestra la fecha de 1993 los derechos de autor.Originalmente, el software funcionó bien con bases de datos relativamente pequeños, pero las pruebas mostraron algunas circunstancias que causaban la corrupción de los datos. Por ejemplo, el tamaño de los archivos de más de 10 MB eran problemáticos (tenga en cuenta que la mayoría de los discos duros eran más pequeños que 500 MB en ese entonces),
- 7. y el manual de Cómo empezar advierte sobre una serie de circunstancias en las que los controladores de dispositivo obsoletos o configuraciones incorrectas puede causar la pérdida de datos. Con la eliminación gradual de Windows 95, 98 y ME, la mejora de la confiabilidad de la red, y el lanzamiento de Microsoft de 8 Service Pack para el Jet Data base Engine, la fiabilidad de las bases de datos de Access se ha mejorado enormemente tanto en tamaño como en número de usuarios.
- 8. Fechas de lanzamientos 1992 Access 1.0 1993 Access 1.1 1994 Access 2.0 1995 Access 95 1997 Access 97 2000 Access 2000 2001 Access XP o 2002 2003 Access 2003 2007 Access 2007

CLUSTER
El término cluster (a veces españolizado como clúster) se aplica a los conjuntos o conglomerados de computadoras construidos mediante la utilización de hardwares comunes y que se comportan como si fuesen una única computadora.
Hoy en día desempeñan un papel importante en la solución de problemas de las ciencias, lasingenierías y del comercio moderno.
La tecnología de clústeres ha evolucionado en apoyo de actividades que van desde aplicaciones de supercómputo y software de misiones críticas, servidores web y comercio electrónico, hasta bases de datos de alto rendimiento, entre otros usos.
El cómputo con clústeres surge como resultado de la convergencia de varias tendencias actuales que incluyen la disponibilidad de microprocesadores económicos de alto rendimiento y redes de alta velocidad, el desarrollo de herramientas de software para cómputo distribuido de alto rendimiento, así como la creciente necesidad de potencia computacional para aplicaciones que la requieran.
Simplemente, un clúster es un grupo de múltiples ordenadores unidos mediante una red de alta velocidad, de tal forma que el conjunto es visto como un único ordenador, más potente que los comunes de escritorio.
Los clústeres son usualmente empleados para mejorar el rendimiento y/o la disponibilidad por encima de la que es provista por un solo computador típicamente siendo más económico que computadores individuales de rapidez y disponibilidad comparables.
De un clúster se espera que presente combinaciones de los siguientes servicios:
La construcción de los ordenadores del clúster es más fácil y económica debido a su flexibilidad: pueden tener todos la misma configuración de hardware y sistema operativo (clúster homogéneo), diferente rendimiento pero con arquitecturas y sistemas operativos similares (clúster semihomogéneo), o tener diferente hardware y sistema operativo (clúster heterogéneo), lo que hace más fácil y económica su construcción.
Para que un clúster funcione como tal, no basta solo con conectar entre sí los ordenadores, sino que es necesario proveer un sistema de manejo del clúster, el cual se encargue de interactuar con el usuario y los procesos que corren en él para optimizar el funcionamiento.
HISTORIA
HISTORIA
El origen del término y del uso de este tipo de tecnología es desconocido pero se puede considerar que comenzó a finales de los años cincuenta y principios de los sesenta.
La base formal de la ingeniería informática de la categoría como un medio de hacer trabajos paralelos de cualquier tipo fue posiblemente inventado por Gene Amdahl de IBM, que en 1967 publicó lo que ha llegado a ser considerado como el papel inicial de procesamiento paralelo: la Ley de Amdahl que describe matemáticamente el aceleramiento que se puede esperar paralelizando cualquier otra serie de tareas realizadas en una arquitectura paralela.
Este artículo define la base para la ingeniería de la computación tanto multiprocesador y computación clúster, en donde el principal papel diferenciador es si las comunicaciones interprocesador cuentan con el apoyo «dentro» de la computadora (por ejemplo, en una configuración personalizada para el bus o la red de las comunicaciones internas) o «fuera» del ordenador en una red «commodity».
En consecuencia, la historia de los primeros grupos de computadoras está más o menos directamente ligado a la historia de principios de las redes, como una de las principales motivaciones para el desarrollo de una red para enlazar los recursos de computación, de hecho la creación de un clúster de computadoras. Las redes de conmutación de paquetes fueron conceptualmente inventados por la corporación RAND en 1962.
Utilizando el concepto de una red de conmutación de paquetes, el proyecto ARPANET logró crear en 1969 lo que fue posiblemente la primera red de computadoras básico basadas en el clúster de computadoras por cuatro tipos de centros informáticos (cada una de las cuales fue algo similar a un «clúster» pero no un «commodity cluster» como hoy en día lo entendemos).
El proyecto ARPANET creció y se convirtió en lo que es ahora Internet. Se puede considerar como «la madre de todos los clústeres» (como la unión de casi todos los recursos de cómputo, incluidos los clústeres, que pasarían a ser conectados).
También estableció el paradigma de uso de computadoras clústeres en el mundo de hoy: el uso de las redes de conmutación de paquetes para realizar las comunicaciones entre procesadores localizados en los marcos de otro modo desconectados.
El desarrollo de la construcción de PC por los clientes y grupos de investigación procedió a la par con la de las redes y el sistema operativo Unix desde principios de la década de los años setenta, como TCP/IP y el proyecto de la Xerox PARC proyecto y formalizado para protocolos basados en la red de comunicaciones.
El núcleo del sistema operativo fue construido por un grupo de DEC PDP-11 minicomputadoras llamado C.mmp en C-MU en 1971.
Sin embargo, no fue hasta alrededor de 1983 que los protocolos y herramientas para el trabajo remoto facilitasen la distribución y el uso compartido de archivos fueran definidos (en gran medida dentro del contexto de BSD Unix, e implementados por Sun Microsystems) y, por tanto llegar a disponerse comercialmente, junto con una compartición del sistema de ficheros.
El primer producto comercial de tipo clúster fue ARCnet, desarrollada en 1977 por Datapoint pero no obtuvo un éxito comercial y los clústeres no consiguieron tener éxito hasta que en 1984 VAXcluster produjeran el sistema operativo VAX/VMS.
El ARCnet y VAXcluster no solo son productos que apoyan la computación paralela, pero también comparten los sistemas de archivos y dispositivos periféricos.
La idea era proporcionar las ventajas del procesamiento paralelo, al tiempo que se mantiene la fiabilidad de los datos y el carácter singular. VAXcluster, VMScluster está todavía disponible en los sistemas de HP OpenVMS corriendo en sistemas Itanium y Alpha.
Otros dos principios comerciales de clústeres notables fueron el Tandem Himalaya (alrededor 1994 de con productos de alta disponibilidad) y el IBM S/390 Parallel Sysplex (también alrededor de 1994, principalmente para el uso de la empresa).
La historia de los clústeres de computadoras estaría incompleta sin señalar el papel fundamental desempeñado por el desarrollo del software de PVM (parallel virtual machine: ‘máquina virtual paralela’).
Este software de fuente abierta basado en comunicaciones TCP/IP permitió la creación de un superordenador virtual ―un clúster HPC― realizada desde cualquiera de los sistemas conectados TCP/IP.
De forma libre los clústeres heterogéneos han constituido la cima de este modelo logrando aumentar rápidamente en FLOPS globalmente y superando con creces la disponibilidad incluso de los más caros superordenadores.
PVM y el empleo de PC y redes de bajo costo llevó, en 1993, a un proyecto de la NASA para construir supercomputadoras de clústeres.
En 1995, la invención de la Beowulf ―un estilo de clúster― una granja de computación diseñada según un producto básico de la red con el objetivo específico de «ser un superordenador» capaz de realizar firmemente y cálculos paralelos HPC.
Esto estimuló el desarrollo independiente de la computación Grid como una entidad, a pesar de que el estilo Grid giraba en torno al del sistema operativo Unix y el Arpanet.

ARREGLO DE DISCOS
Arrays de disco son parte integrante de almacenamiento de alto rendimiento sistemas, y su magnitud e importancia son cada vez más como un acceso continuo a la información se convierte en fundamental para el día a día de los negocios modernos.
Los arrays de disco organizan su almacenamiento de datos en Unidades lógica , o LU, que aparecen como espacios de bloque lineal en el os de su cliente.
Los arrays de disco organizan su almacenamiento de datos en Unidades lógica , o LU, que aparecen como espacios de bloque lineal en el os de su cliente.
Una matriz de discos pequeños, con pocos discos, puede soporta hasta 8 UGM, mientras que un gran r uno, con cientos de disco unidades, puede soportar miles de personas.
Cada LU tiene típicamente un dado el nivel de RAID, una asignación de redundancia en uno o subyacentes más unidades de disco físico. Esta decisión es hecha en LU-tiempo de creación, y normalmente es irrevocable: Una vez que la LU ha sido formateado, cambiando su nivel de RAID requiere de copiar todos los datos en un LU.
Mientras que los controladores de RAID de hardware que se disponían hace mucho tiempo, siempre que se requiere costosas unidades de disco duro SCSI y destinados a el servidor y el mercado de la informática. Algunas de las ventajas en el uso de la tecnología SCSI de son que se pueden colocar hasta 15 dispositivos en un bus, transferencias independientes de datos, intercambio en caliente, así como mucho más alto MTBF (Mean Time Between Failures).
Alrededor de 1997, con la introducción de ATAPI-4 (lo que Ultra-DMA Mode-0, que permitió la transferencia rápida de datos con la utilización de menos CPU) los primeros controladores RAID ATA se introdujeron (como tarjetas de expansión PCI).
Dado que RAID SISTEMA tienden a usar muchas unidades, unidades ATA y su ventaja en precios hizo posible la construcción de sistemas RAID a un costo mucho más barato que con SCSI.
Los sistemas más baratos RAID \se dirigían al mercado de consumo, donde los usuarios querían tolerancia a fallos de RAID sin necesidad de invertir en costosos discos SCSI.
Esto significa que el rendimiento fuera de grandes lecturas simples y generales.
La seguridad de datos se ve afectada si no hay un respaldo para terminar.

RAID 1
Un RAID 1 crea una copia exacta (o espejo) de un conjunto de datos en dos o más discos. Esto resulta útil cuando el rendimiento en lectura es más importante que la capacidad. Un conjunto RAID 1 sólo puede ser tan grande como el más pequeño de sus discos. Un RAID 1 clásico consiste en dos discos en espejo, lo que incrementa exponencialmente la fiabilidad respecto a un solo disco; es decir, la probabilidad de fallo del conjunto es igual al producto de las probabilidades de fallo de cada uno de los discos (pues para que el conjunto falle es necesario que lo hagantodos sus discos).
Adicionalmente, dado que todos los datos están en dos o más discos, con hardware habitualmente independiente, el rendimiento de lectura se incrementa aproximadamente como múltiplo lineal del número del copias; es decir, un RAID 1 puede estar leyendo simultáneamente dos datos diferentes en dos discos diferentes, por lo que su rendimiento se duplica. Para maximizar los beneficios sobre el rendimiento del RAID 1 se recomienda el uso de controladoras de disco independientes, una para cada disco (práctica que algunos denominan splitting oduplexing).
Como en el RAID 0, el tiempo medio de lectura se reduce, ya que los sectores a buscar pueden dividirse entre los discos, bajando el tiempo de búsqueda y subiendo la tasa de transferencia, con el único límite de la velocidad soportada por la controladora RAID. Sin embargo, muchas tarjetas RAID 1 IDE antiguas leen sólo de un disco de la pareja, por lo que su rendimiento es igual al de un único disco. Algunas implementaciones RAID 1 antiguas también leen de ambos discos simultáneamente y comparan los datos para detectar errores. La detección y corrección de errores en los discos duros modernos hacen esta práctica poco útil.
Al escribir, el conjunto se comporta como un único disco, dado que los datos deben ser escritos en todos los discos del RAID 1. Por tanto, el rendimiento no mejora.
El RAID 1 tiene muchas ventajas de administración. Por ejemplo, en algunos entornos 24/7, es posible «dividir el espejo»: marcar un disco como inactivo, hacer una copia de seguridad de dicho disco y luego «reconstruir» el espejo. Esto requiere que la aplicación de gestión del conjunto soporte la recuperación de los datos del disco en el momento de la división. Este procedimiento es menos crítico que la presencia de una característica de snapshot en algunos sistemas de archivos, en la que se reserva algún espacio para los cambios, presentando una vista estática en un punto temporal dado del sistema de archivos. Alternativamente, un conjunto de discos puede ser almacenado de forma parecida a como se hace con las tradicionales cintas.
RAID 2

Un RAID 2 divide los datos a nivel de bits en lugar de a nivel de bloques y usa un código de Hamming para la corrección de errores. Los discos son sincronizados por la controladora para funcionar al unísono. Éste es el único nivel RAID original que actualmente no se usa. Permite tasas de trasferencias extremadamente altas.
Teóricamente, un RAID 2 necesitaría 39 discos en un sistema informático moderno: 32 se usarían para almacenar los bits individuales que forman cada palabra y 7 se usarían para la corrección de errores.
RAID 3

Un RAID 3 usa división a nivel de bytes con un disco de paridad dedicado. El RAID 3 se usa rara vez en la práctica. Uno de sus efectos secundarios es que normalmente no puede atender varias peticiones simultáneas, debido a que por definición cualquier simple bloque de datos se dividirá por todos los miembros del conjunto, residiendo la misma dirección dentro de cada uno de ellos. Así, cualquier operación de lectura o escritura exige activar todos los discos del conjunto, suele ser un poco lento porque se producen cuellos de botella. Son discos paralelos pero no son independientes (no se puede leer y escribir al mismo tiempo).
En el ejemplo del gráfico, una petición del bloque «A» formado por los bytes A1 a A6 requeriría que los tres discos de datos buscaran el comienzo (A1) y devolvieran su contenido. Una petición simultánea del bloque «B» tendría que esperar a que la anterior concluyese.
RAID 4

Un RAID 4, también conocido como IDA (acceso independiente con discos dedicados a la paridad) usa división a nivel de bloques con un disco de paridad dedicado. Necesita un mínimo de 3 discos físicos. El RAID 4 es parecido al RAID 3 excepto porque divide a nivel de bloques en lugar de a nivel de bytes. Esto permite que cada miembro del conjunto funcione independientemente cuando se solicita un único bloque. Si la controladora de disco lo permite, un conjunto RAID 4 puede servir varias peticiones de lectura simultáneamente. En principio también sería posible servir varias peticiones de escritura simultáneamente, pero al estar toda la información de paridad en un solo disco, éste se convertiría en el cuello de botella del conjunto.
En el gráfico de ejemplo anterior, una petición del bloque «A1» sería servida por el disco 0. Una petición simultánea del bloque «B1» tendría que esperar, pero una petición de «B2» podría atenderse concurrentemente.
RAID 5

Un RAID 5 usa división de datos a nivel de bloques distribuyendo la información de paridad entre todos los discos miembros del conjunto. El RAID 5 ha logrado popularidad gracias a su bajo coste de redundancia. Generalmente, el RAID 5 se implementa con soporte hardware para el cálculo de la paridad. RAID 5 necesitará un minimo de 3 discos para ser implementado.
En el gráfico de ejemplo anterior, una petición de lectura del bloque «A1» sería servida por el disco 0. Una petición de lectura simultánea del bloque «B1» tendría que esperar, pero una petición de lectura de «B2» podría atenderse concurrentemente ya que seria servida por el disco 1.
Cada vez que un bloque de datos se escribe en un RAID 5, se genera un bloque de paridad dentro de la misma división (stripe). Un bloque se compone a menudo de muchos sectores consecutivos de disco. Una serie de bloques (un bloque de cada uno de los discos del conjunto) recibe el nombre colectivo de división (stripe). Si otro bloque, o alguna porción de un bloque, es escrita en esa misma división, el bloque de paridad (o una parte del mismo) es recalculada y vuelta a escribir. El disco utilizado por el bloque de paridad está escalonado de una división a la siguiente, de ahí el término «bloques de paridad distribuidos». Las escrituras en un RAID 5 son costosas en términos de operaciones de disco y tráfico entre los discos y la controladora.
Los bloques de paridad no se leen en las operaciones de lectura de datos, ya que esto sería una sobrecarga innecesaria y disminuiría el rendimiento. Sin embargo, los bloques de paridad se leen cuando la lectura de un sector de datos provoca un error de CRC. En este caso, el sector en la misma posición relativa dentro de cada uno de los bloques de datos restantes en la división y dentro del bloque de paridad en la división se utilizan para reconstruir el sector erróneo. El error CRC se oculta así al resto del sistema. De la misma forma, si falla un disco del conjunto, los bloques de paridad de los restantes discos son combinados matemáticamente con los bloques de datos de los restantes discos para reconstruir los datos del disco que ha fallado «al vuelo».
Lo anterior se denomina a veces Modo Interino de Recuperación de Datos (Interim Data Recovery Mode). El sistema sabe que un disco ha fallado, pero sólo con el fin de que el sistema operativo pueda notificar al administrador que una unidad necesita ser reemplazada: las aplicaciones en ejecución siguen funcionando ajenas al fallo. Las lecturas y escrituras continúan normalmente en el conjunto de discos, aunque con alguna degradación de rendimiento. La diferencia entre el RAID 4 y el RAID 5 es que, en el Modo Interno de Recuperación de Datos, el RAID 5 puede ser ligeramente más rápido, debido a que, cuando el CRC y la paridad están en el disco que falló, los cálculos no tienen que realizarse, mientras que en el RAID 4, si uno de los discos de datos falla, los cálculos tienen que ser realizados en cada acceso.
El RAID 5 requiere al menos tres unidades de disco para ser implementado. El fallo de un segundo disco provoca la pérdida completa de los datos.
El número máximo de discos en un grupo de redundancia RAID 5 es teóricamente ilimitado, pero en la práctica es común limitar el número de unidades. Los inconvenientes de usar grupos de redundancia mayores son una mayor probabilidad de fallo simultáneo de dos discos, un mayor tiempo de reconstrucción y una mayor probabilidad de hallar un sector irrecuperable durante una reconstrucción. A medida que el número de discos en un conjunto RAID 5 crece, el MTBF (tiempo medio entre fallos) puede ser más bajo que el de un único disco. Esto sucede cuando la probabilidad de que falle un segundo disco en los N-1 discos restantes de un conjunto en el que ha fallado un disco en el tiempo necesario para detectar, reemplazar y recrear dicho disco es mayor que la probabilidad de fallo de un único disco. Una alternativa que proporciona una protección de paridad dual, permitiendo así mayor número de discos por grupo, es el RAID 6.
Algunos vendedores RAID evitan montar discos de los mismos lotes en un grupo de redundancia para minimizar la probabilidad de fallos simultáneos al principio y el final de su vida útil.
Las implementaciones RAID 5 presentan un rendimiento malo cuando se someten a cargas de trabajo que incluyen muchas escrituras más pequeñas que el tamaño de una división (stripe). Esto se debe a que la paridad debe ser actualizada para cada escritura, lo que exige realizar secuencias de lectura, modificación y escritura tanto para el bloque de datos como para el de paridad. Implementaciones más complejas incluyen a menudo cachés de escritura no volátiles para reducir este problema de rendimiento.
En el caso de un fallo del sistema cuando hay escrituras activas, la paridad de una división (stripe) puede quedar en un estado inconsistente con los datos. Si esto no se detecta y repara antes de que un disco o bloque falle, pueden perderse datos debido a que se usará una paridad incorrecta para reconstruir el bloque perdido en dicha división. Esta potencial vulnerabilidad se conoce a veces como «agujero de escritura». Son comunes el uso de caché no volátiles y otras técnicas para reducir la probabilidad de ocurrencia de esta vulnerabilidad.
MOTOR BASE DE DATOS
El Motor de base de datos es el servicio principal para almacenar, procesar y proteger datos. El Motor de base de datos proporciona acceso controlado y procesamiento de transacciones rápido para cumplir con los requisitos de las aplicaciones consumidoras de datos más exigentes de su empresa.
Use Motor de base de datos para crear bases de datos relacionales para el procesamiento de transacciones en línea o datos de procesamiento analítico en línea. Esto incluye la creación de tablas para almacenar datos y objetos de base de datos (p.ej., índices, vistas y procedimientos almacenados) para ver, administrar y proteger datos. Puede usar SQL Server Management Studio para administrar los objetos de bases de datos y SQL Server Profiler para capturar eventos de servidor.
PRIMARY KEY
PRIMARY KEY
Una tabla suele tener una columna o una combinación de columnas cuyos valores identifican de forma única cada fila de la tabla. Estas columnas se denominan claves principales de la tabla y exigen la integridad de entidad de la tabla. Puede crear una clave principal mediante la definición de una restricción PRIMARY KEY cuando cree o modifique una tabla.
Una tabla sólo puede tener una restricción PRIMARY KEY y ninguna columna a la que se aplique una restricción PRIMARY KEY puede aceptar valores NULL. Debido a que las restricciones PRIMARY KEY garantizan datos únicos, con frecuencia se definen en una columna de identidad.
Cuando especifica una restricción PRIMARY KEY en una tabla, Motor de base de datos exige la unicidad de los datos mediante la creación de un índice único para las columnas de clave principal.Este índice también permite un acceso rápido a los datos cuando se utiliza la clave principal en las consultas. De esta forma, las claves principales que se eligen deben seguir las reglas para crear índices únicos.
Si se define una restricción PRIMARY KEY para más de una columna, puede haber valores duplicados dentro de la misma columna, pero cada combinación de valores de todas las columnas de la definición de la restricción PRIMARY KEY debe ser única.
Como se muestra en la siguiente ilustración, las columnas ProductID y VendorID de la tabla Purchasing.ProductVendor forman una restricción PRIMARY KEY compuesta para esta tabla. Así se garantiza que la combinación de ProductID y VendorID es única.
´CADENA DE CARACTERES
´CADENA DE CARACTERES
En programación, una cadena de caracteres, palabra, ristra de caracteres o frase (stringen inglés) es una secuencia ordenada de longitud arbitraria (aunque finita) de elementos que pertenecen a un cierto alfabeto. En general, una cadena de caracteres es una sucesión decaracteres (letras, números u otros signos o símbolos).
Desde un punto de vista de la programación, si no se ponen restricciones al alfabeto, una cadena podrá estar formada por cualquier combinación finita de todo el juego caracteres disponibles (las letras de la 'a' a la 'z' y de la 'A' a la 'Z', los números del '0' al '9', el espacio en blanco ' ', símbolos diversos '!', '@', '%', etc). En este mismo ámbito (el de la programación), se utilizan normalmente como un tipo de dato predefinido, para palabras, frases o cualquier otra sucesión de caracteres. En este caso, se almacenan en un vector de datos, o matriz de datos de una sola fila (array en inglés). Las cadenas se pueden almacenar físicamente:
- Seguidas.
- Enlazados letra a letra.
Generalmente son guardados un carácter a continuación de otro por una cuestión de eficiencia de acceso.
Un caso especial de cadena es la que contiene cero caracteres, a esta cadena se la llamacadena vacía; en teoría de autómatas es común denotar a la misma por medio de la letra griega  .
.
.